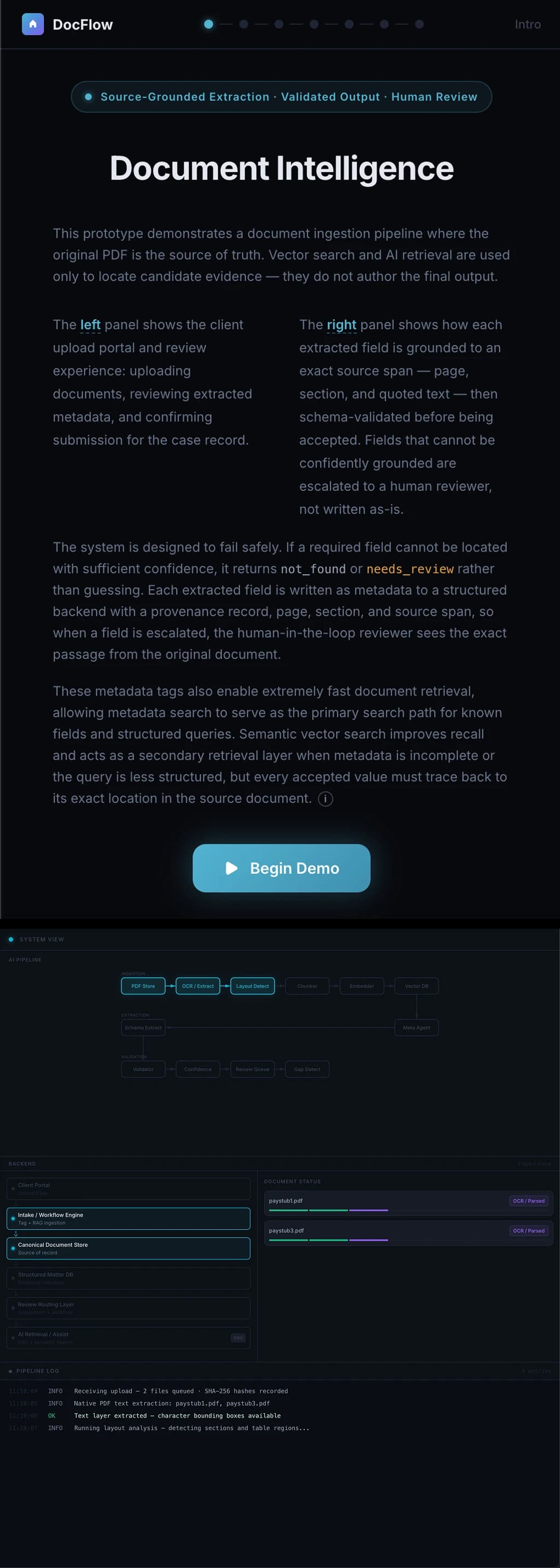
An AI-powered metadata-first document intelligence system for complex PDFs that detects and turns critical information into searchable, structured data, always traceable to the source document. The system combines fast metadata-based retrieval with semantic search as a secondary layer for flexible and unstructured discovery.
Project Type: tech / AI Document Pipeline
Role: Full-Stack Developer
Tech Stack: Next.js, TypeScript, React, OpenAI Embeddings, pgvector, TailwindCSS
Status: Deployed 2023; Updated Prototype 2026
Live Demo: upload-flow
Source-Grounded Extraction · Validated Output · Human Review